
If you’ve ever worked with Kafka in production, you’ve probably dealt with consumer group rebalancing at some point. Most of the time, it’s just background noise. But every now and then, it turns into a full-blown operational headache, especially when your processes have a task that is long.
We ran into this exact scenario when building out a feature that exports large datasets into files on demand. At first glance, it sounded simple: a consumer reads a message, gathers some data, writes it to a file, and stores it on a network path for download. The issue? Some of these tasks could run for close to thirty minutes.
Where Things Went Wrong
In our Kafka setup, each export request lands on a topic. A group of consumers picks them up and starts processing. Nothing special, until a task drags on longer than expected. Kafka expects each consumer to poll the broker at regular intervals. By default, that interval (max.poll.interval.ms) is set to five minutes.
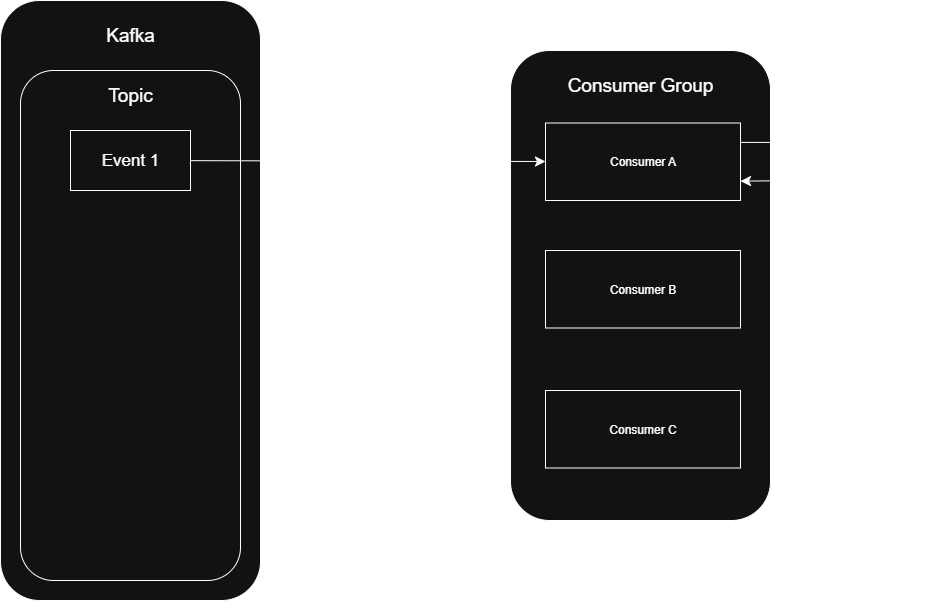
You can probably guess what happened next.
A consumer begins writing a large file, completely focused on the task. But since it’s busy with the task and doesn’t get around to polling in time, Kafka assumes the worst: the consumer must have died. A rebalance is triggered, and its partition is handed off to another consumer.
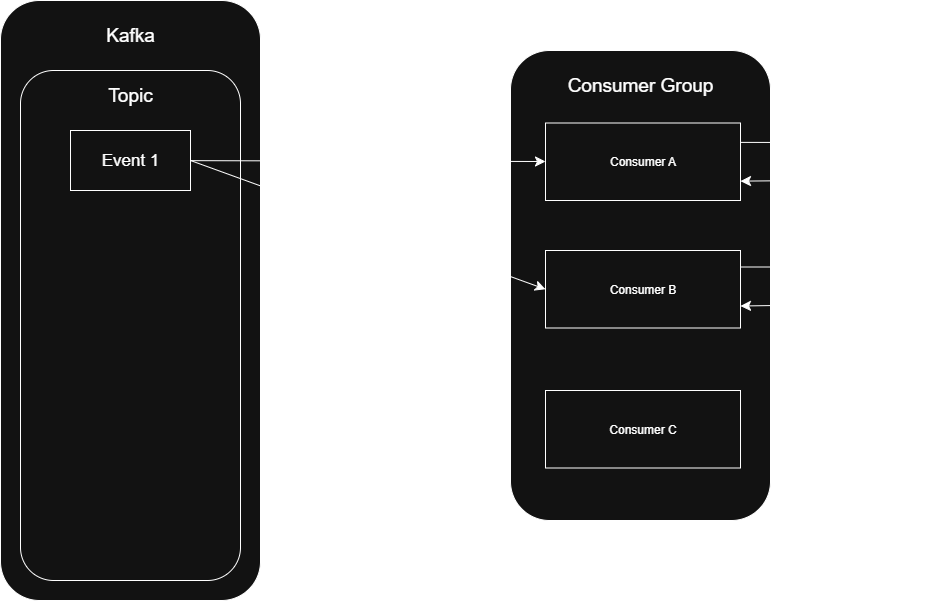
This second consumer picks up where the first one left off but it runs into the exact same delay. Another rebalance is triggered. And the cycle repeats.
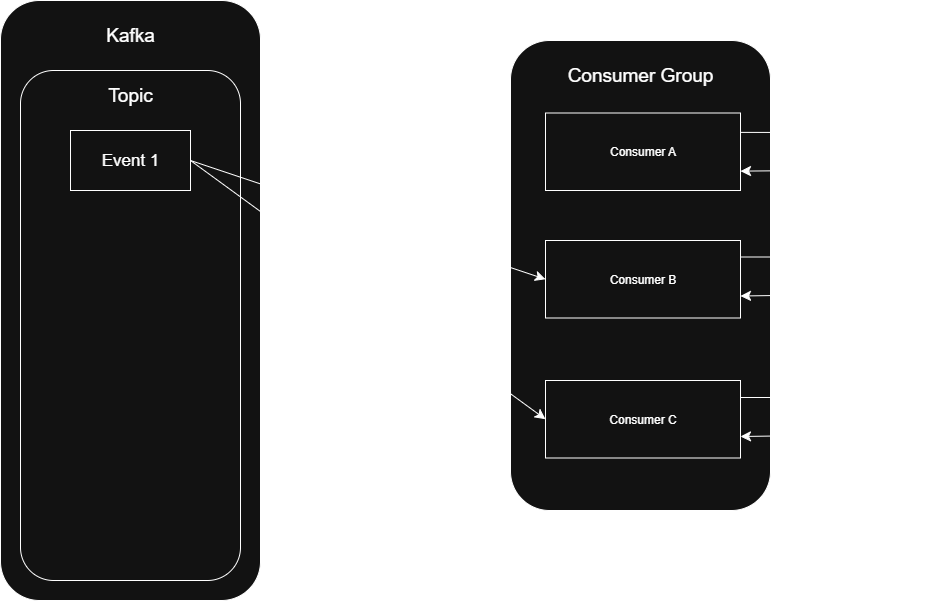
Over time, this created a rebalance spiral where no task ever completed, and every consumer in the group kept getting kicked out.
Why Not Just Increase the Timeout?
We considered bumping up the poll interval. But when you’re dealing with unpredictable file sizes and multiple downstream dependencies, it’s hard to pick a safe value. Set it too low and you’re back in the spiral. Set it too high and real consumer failures go unnoticed for too long.
We also explored the usual suspects: code optimization, splitting files, fire-and-forget models but they either added too much complexity or failed to guarantee data consistency.
Eventually, we landed on something that worked: pause the partition, delegate the heavy lifting to another thread, and resume when done.
How the Fix Works
Instead of letting the Kafka listener get stuck on a long task, we do the following:
As soon as we receive a message that triggers a heavy export, we pause the partition it’s coming from.
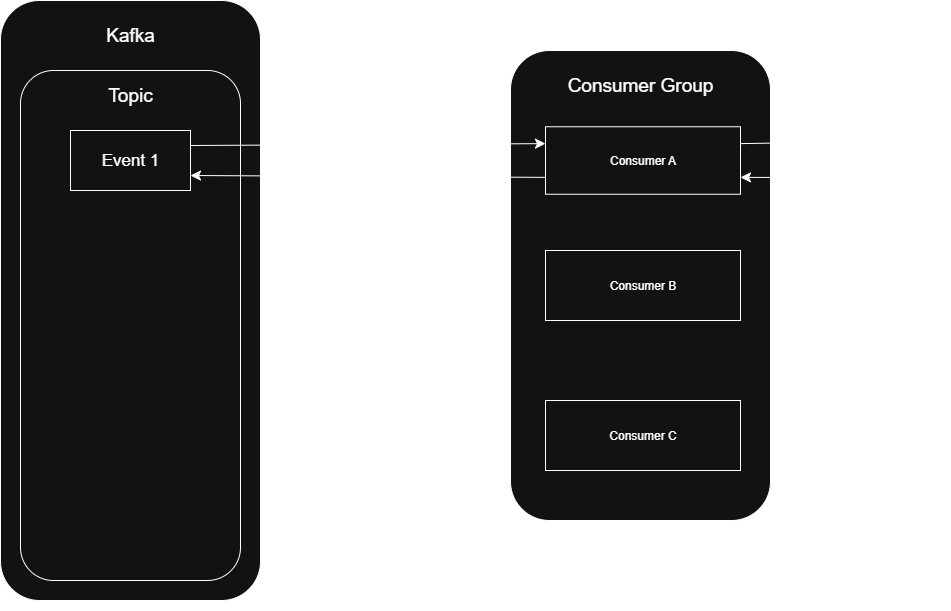
The listener continues polling Kafka at regular intervals but it won’t receive any new records from the paused partition.
Meanwhile, the actual export logic is handed off to a separate thread, freeing up the main listener. We can still enforce a hard timeout by scheduling a task cancellation after checking if the task is done
Once the thread finishes its task, whether successfully or due to timeout, the partition is resumed so the consumer can continue processing the next message.
By doing this, we keep Kafka happy (because we’re still polling) and avoid duplicate work (because we don’t reassign the same partition mid-task).
Here’s a simplified version of what that looks like:
public void handleHeavyRecord(ConsumerRecord<String, String> record) {
// Pause the specific partition
var container = kafkaListenerEndpointRegistry.getListenerContainer("exportListener");
container.pausePartition(record.topicPartition());
// Create Thread Pool
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(THREAD_COUNT);
// Create export task
FutureTask<Void> exportTask = new FutureTask<>(
() -> {
try {
processTask(record);
}
catch (Exception e) {
handleFailure(record, "Exception occured while task was running" + e.toString());
}
finally {
// Resume partition after task has completed or failed
listenerContainer.resume();
}
return null;
}
);
// Start export task
executorService.submit(exportTask);
// Timeout after 30 minutes
executorService.schedule(
() -> {
// Skip if task is already cancelled or has completed
if (exportTask.isCancelled() || exportTask.isDone())
return;
exportTask.cancel(true);
// Resume partition after timeout
listenerContainer.resume();
handleFailure(record, "Export task exceeded time limit");
},
30,
TimeUnit.MINUTES
);
}